
Kim Svensson AI
En moralisk agent

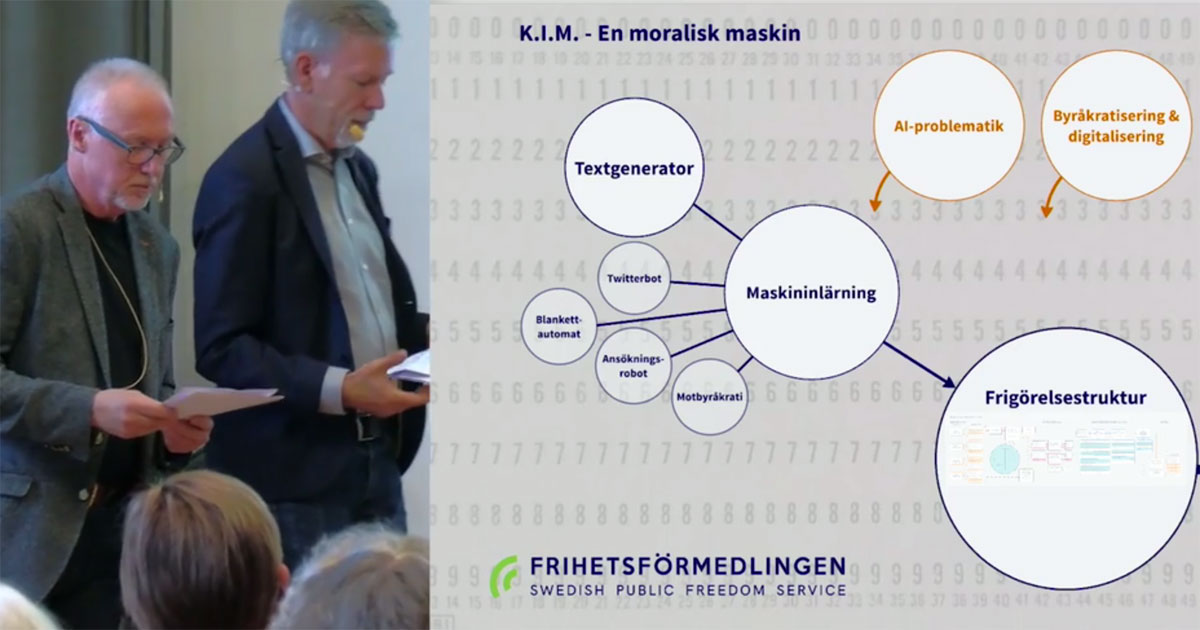
Jag är med i ett spännande konstprojekt, Kim Svensson, AI, vars syfte är att skapa en byråkrat som är en artificiell intelligens. Kim ska vara en moralisk agent, och det har lett till en hel del tankar och diskussioner.
Det är förstås väldigt svårt att skapa en AI som är moralisk på samma sätt som en människa, och många skulle säga att det inte heller är önskvärt.
Med en AI är det både lättare och svårare att skapa en moralisk agent. En AI har alltid ett mål, som att lära sig navigera i en okänd miljö eller att lära sig efterlikna en bild eller text. Det som är svårt med AIn är att bestämma sig för vilket man ska välja som mål när man programmerar AIn. Det som är lättare är att mäta hur långt man är från målet.
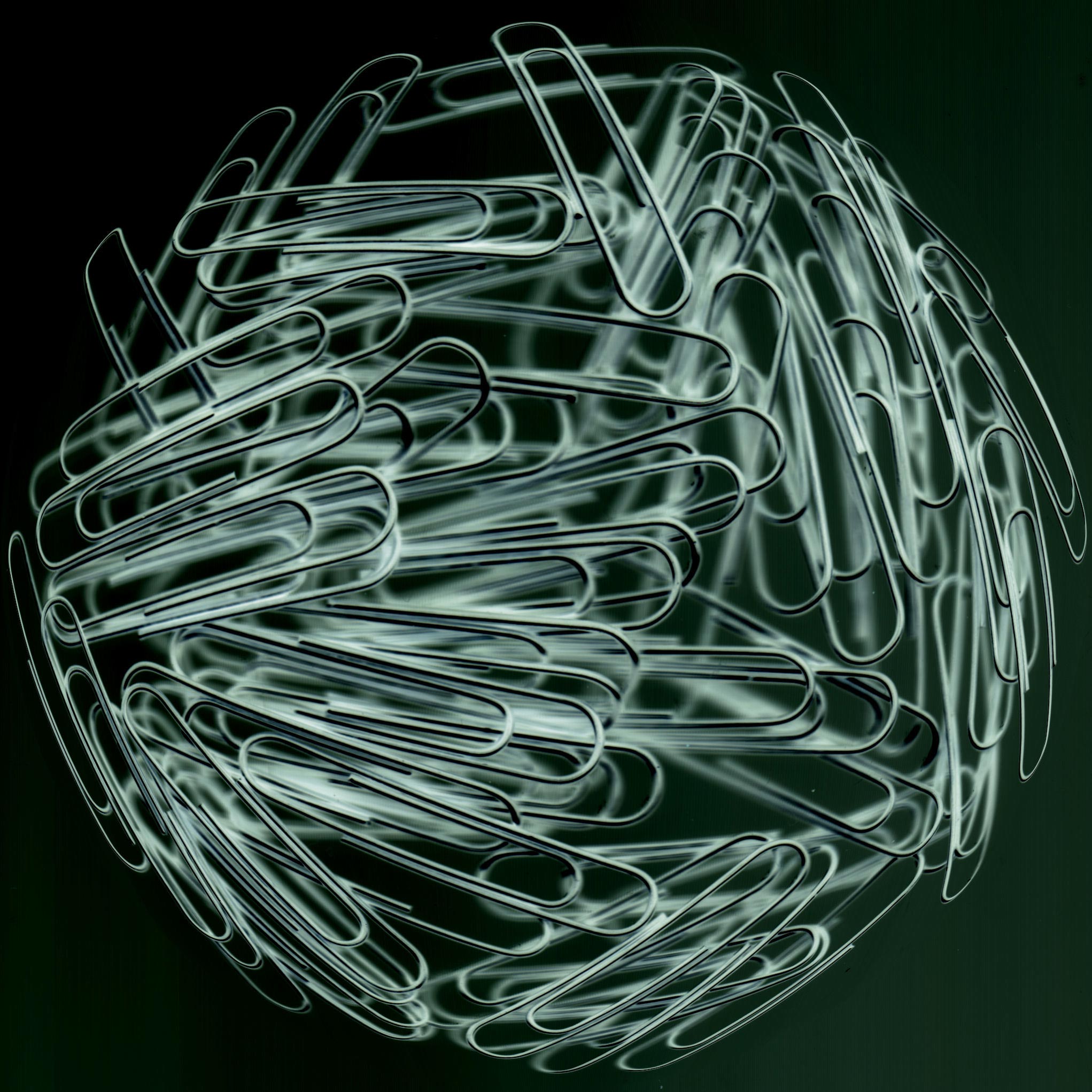
Nick Bostrom, Anders Sandberg och de andra på Future of humanity institute i Oxford har ett roligt exempel som är en robot som gör gem. Om roboten är kraftfull och har detta som enda mål kan det snabbt spåra ur.
Här är ett föredrag av Anders Sandberg där han redogör för argumentet:

Själva mätandet av måluppfyllelsen är oftast trivialt. Det finns matematiska funktioner för det. I gem-robotens fall är ju det enda som räknas hur många gem som tillverkas.
En AI lär sig ofta genom att starta med en slumpmässig uppfattning om sitt problem. Man mäter hur långt man är från målet genom en förlust- eller kostnadsfunktion. Därefter förändrar man AIns modell lite grand, och ser om man kom närmare målet.
De flesta AI-system som byggs är så här enkla – ett enda värde som ska optimeras, och ingen överordnad funktion som i sin tur mäter om det man gjort är bra. Den överordnade funktionen får vi människor än så länge sköta själva.
Men vilken otrolig kapacitet de senaste årens AI-experiment har haft. Från style transfer för bilder och video till att lära sig vinna i spel som Go som man för bara något år sen sa att bara människan kunde klara. Framgångarna har varit så stora att det är lätt att missa begränsningarna och den ofta väldigt enkla modell som ligger under.
Att med den enkla definitionen här skapa en moralisk agent är alltså inte så svårt, eftersom moral är det goda som i sin tur är det mål som man väljer för sin AI. Vill man skapa en moralisk agent som är en byråkrat finns det mycket att välja mellan. Man kan tänka sig en nitisk tjänsteman som letar efter fel i olika system, någon som underlättar för folk som känner sig fast i byråkratin, eller nidbilden av en byråkrat som stoppar till hela den administrativa apparaten genom att fylla den med värdelös information.
“Sentiment” är en speciell kategori som man kan utforska. Sentiment analysis (attitydanalys eller tonalitetsanalys på svenska) är ett område som tar texter och sätter ett värde på dem, på en skala, positivt eller negativt. Det används ibland för att sortera exempelvis online-recensioner automatiskt. I den enklaste versionen sätter man ett värde på varje ord och summerar värdet för varje text. Här är ett ställe att börja om man kör Python.
I en lite mer komplicerad men helt fantastisk demonstration visar Rob Speer hur man med enkla medel och standardiserade datamängder kan bygga en maskin som klassificerar texter efter sentiment, men som visar sig vara rasistisk! Demon är lätt att följa från länken här, och om man vill kan man sätta upp Jupyter på sin dator (eller Googles Colaboratory) och köra med egna data.
Varje in-rad är det man matar in i systemet, och så följer värdet på nästa rad:
In [15]: text_to_sentiment(“Let’s go get Italian food”)
Out[15]: 2.0429166109408983
In [16]: text_to_sentiment(“Let’s go get Chinese food”)
Out[16]: 1.4094033658140972
In [17]: text_to_sentiment(“Let’s go get Mexican food”)
Out[17]: 0.38801985560121732
Det enda som varieras här är landet, och italiensk mat får mycket positivt omdöme, kinesisk tydligt lägre och mexikansk väldigt lågt värde. Detta är fördomar i sin renaste form! Det blir ännu tydligare när han tar motsvarande exempel med kvinnonamn, där de kvinnonamn som associeras med svarta får väldigt låga värden.
Anledningen till att det blir så här är ju att de fördomar som finns i datamängderna kommer fram i resultatet. Och det är en väldigt svår nöt att knäcka hur man ska komma till rätta med detta. Det finns en övertro på att de artificiella agenter vi vill ska ta över vissa av våra tråkiga arbetsuppgifter dessutom ska göra sin uppgift helt opartiskt och etiskt oklanderligt, eftersom de har programmerats efter avsiktliga regler, men för att det ska fungera får man uppenbarligen inte lära upp dem på ett material som innehåller de fördomar som vi ville bli av med.
Jag tror att vilket mål man än väljer så riskerar det att bli fel, precis som att new public management (som liknar de här systemen väldigt mycket) är dömt att få oönskade resultat när vinstmaximering och liknande “blinda” värden får styra verksamhetsutvecklingen.
Ett sätt att få syn på, och förbereda sig på, oönskade resultat av system med alltför enkla mål är att studera det som ibland kallas “reward hacking”.
I reward hacking sätter man upp ett mål, som ju är uttänkt för att det är ett tecken på att systemet fungerar väl, och så “hackas” det målet, genom att systemet hittar oönskade sätt att få den belöning som målet innebär.
I det här blogginlägget och den här listan finns många sådana exempel som både är sedelärande och inspirerande. Som artificiella djur som utvecklas för att bli snabba och som under utvecklingen växer sig så stora att de kan uppnå hög hastighet genom att helt enkelt trilla! Eller en agent som dödar sig själv vid slutet av nivå 1 för att undvika att dö i nivå 2…
Det ska bli roligt att utforska rymden av möjliga mål för en byråkratisk AI.
– – – –
Artikeln är tidigare publicerad som bloggpost på tankesmedjan Infontology där Simon Winter är verksam som analytiker.
❯ Till bloggposten
Att titta runt i en vektorrymd
Inom ramen för projektet Kim Svensson, AI håller jag på att utforska olika tekniska lösningar. Tekniken ska vara sådan att den både bygger på modern AI/machine learning och producerar texter som är relevant för en byråkrat.
Ett av de första verktygen jag har testat heter Ketchum och är en rätt liten snurra för att visa ordassociationer från Fasttext-projektet.
Först lite om Fasttext, som är ett projekt från Facebook för textklassificering och vektorrepresentation av texter.
Jag ska skriva ett annat inlägg om vektorrepresentationer. Kortfattat betyder det i det här fallet att man tar varje enskilt ord i den vokabulär som bygger upp texten och ger den en punkt i en flerdimensionell rymd. Genom det sätt man sätter ut punkter kommer ord med liknande betydelse att hamna intill varann. Det här bygger på en hypotes som heter distributional semantics och som går ut på att om man tittar på ords användning så kommer ord med liknande betydelse att användas på liknande sätt. (Det står att Firth stått för att göra hypotesen populär, men den stämmer också bra med det jag förstått av den senare Wittgenstein som säger att ordens användning bestämmer deras betydelse.)
En viktig anmärkning i sammanhanget tycker jag är att det inte finns någon semantisk representation i den här modellen. Det enda som finns är rymden av ord, och var ett ord hamnar bestäms endast av var de andra orden befinner sig.
Nåväl, det som Fasttext-projektet har gjort är bland annat att träna upp ett nätverk på många olika texter. För svenska har man tagit svenska Wikipedia. Att träna ett nätverk betyder i det här fallet att man har bestämt de olika ordens positioner i den multidimensionella rymden. Man har använt sig av en rymd i 300 dimensioner, och den är ju då väldigt svår att visualisera. Om man vill titta på rymden kan man använda tekniker för dimensionsreduktion (som t-SNE) eller så får man utforska rymden på andra sätt.
Så här kan en liknande rymd se ut i två dimensioner:
Det här är ju bara två dimensioner av 300, så det som ligger nära varann i de här två dimensionerna kan ligga långt ifrån eller närmare i någon annan dimension. Det är väldigt abstrakt med de här dimensionerna, men man får vänja sig vid det. Ju förr man kan se en punkt i många dimensioner framför sig, desto snabbare inser man styrkan (och svagheterna) i modellen.
Det lilla verktyget Ketchum tar de färdigtränade Fasttext-vektorerna och ger ett litet interface där man kan utforska närliggande ord.
Så här kan det se ut:
Det är lätt att verktyget kommer in på något som liknar ordlikhet, snarare än semantiska associationer. Det kan bero på att det först hittar böjningsformer, och att hela historiken spelar roll för hur den fortsätter att leta. Det är spännande att det kan hitta “omutlig” i associationerna till byråkrati.
Med grönsaker känns det som att fungerar ganska bra, liksom billackering:
Det är relativt lätt att sätta upp Ketchum.
Lite teknik: jag installerade beroendena, var tvungen att använda sudo. Jag kör Python 3 så då blir installationen med pip3. Det var något med print(f) som inte fungerade, och jag orkade inte ta reda på vad som var fel, så jag tog helt enkelt bort f-et, så gick det bra. Filen jag laddade ner från Fasttext var inte zippad, men Ketchum förutsatte det… Det slutade med att jag zippade den så att programmet fick tugga sig igenom på rätt sätt. När jag körde igång tog det flera timmar, men sen satte den upp en lokal server. När jag startade systemet andra gången gick det igång genast. Klicka inte på länken till vektorerna, den är en väldigt stor fil…
– – – –
Artikeln är tidigare publicerad som en bloggpost på tankesmedjan Infontology där Simon Winter är verksam som analytiker.
❯ Till bloggposten